Your LangGraph Agents Are Deadlocking. Here’s the Fix.
How we applied a 60-year-old OS algorithm to prevent deadlocks in multi-AI-agent systems
You have three AI agents. A researcher that calls the OpenAI API and browses the web. A summarizer that calls the API. A fact-checker that needs both. You give them a task. They start working. Then they stop. No errors. No timeout. They're just... frozen.
Your agents are deadlocked, and nothing in your stack is telling you.
The researcher is holding 5 API slots and waiting for the browser. The fact-checker is holding the browser and waiting for API slots. Neither can proceed. Neither will ever proceed. Your max_iterations=50 eventually kills them, but you've burned tokens, time, and money -and the task failed silently.
This is not a bug in your code. This is a fundamental problem with how multi-agent systems share resources. And it was solved in 1965.
The Problem: Why Multi-Agent Systems Deadlock
When multiple AI agents share limited resources, four conditions create deadlock:
- Mutual exclusion -only one agent can use a resource at a time (e.g., a code interpreter)
- Hold and wait -an agent holds some resources while waiting for others
- No preemption -you can't forcibly take resources from an agent
- Circular wait -Agent A waits for B, B waits for A
In LangGraph and LangChain, this happens constantly:
- API rate limits -60 OpenAI requests/minute shared across 5 agents
- Tool access -a code interpreter that only 1 agent can use at a time
- Token budgets -100K tokens/minute pooled across agents
- Database connections -10 connections shared by 20 agents
The current "solution" in every framework? max_iterations. Kill the agent after N steps. That's not a solution -it's a timer strapped to a bomb.
The Fix: 5 Lines of Code
pip install agentguard-ai
from agentguard.langgraph import AgentGuard, guarded_tool
# Set up the guard
guard = AgentGuard()
guard.add_resource("openai_api", capacity=60, category="api_rate_limit")
guard.add_resource("browser", capacity=1, category="tool_slot")
researcher = guard.register_agent("researcher", max_needs={"openai_api": 10, "browser": 1})
# Wrap your tools -that's it
@guarded_tool(guard, researcher, {"openai_api": 2, "browser": 1})
def research(query: str) -> str:
results = openai.chat(f"Research: {query}")
page = browse(query)
return summarize(results, page)
# Resources are automatically acquired before the function runs
# and released after it returns (or raises an exception)
result = research("latest advances in AI agents")
Before every resource grant, AgentGuard asks: "If I give this agent these resources, can every agent in the system still finish?" If the answer is no, the request waits until it's safe. No deadlock. Ever.
How It Works: The Banker's Algorithm in 30 Seconds
Edsger Dijkstra published the Banker's Algorithm in 1965. The idea is simple:
- Every agent declares its maximum resource needs upfront
- Before granting any request, simulate: "Give them the resources. Now, can I find an order where everyone finishes?"
- If yes (safe state), grant the request
- If no (unsafe state), queue the request until it becomes safe
The simulation works by iteratively finding agents whose remaining needs can be met with currently available resources, marking them as "will finish," reclaiming their resources, and repeating. If everyone eventually finishes, the state is safe.
AgentGuard runs this check in microseconds (C++ core, O(n^2 * m) where n = agents, m = resource types). For typical multi-agent systems, it's invisible overhead.
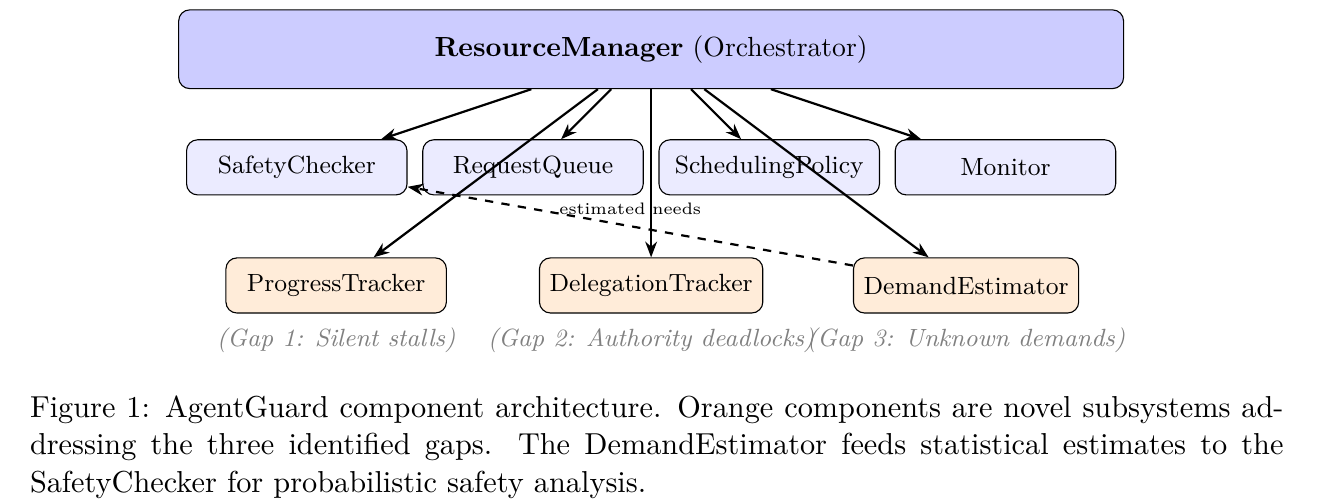
Beyond the Textbook: Three Problems Dijkstra Never Anticipated
Classical Banker's works for OS processes. AI agents are different. We found three gaps and built solutions for each.
Problem 1: Agents Get Stuck and Nobody Notices
An LLM enters an infinite reasoning loop. A tool call hangs. The agent holds resources, everyone else waits, and the whole system freezes. Every framework has this problem.
AgentGuard's Progress Monitor tracks named progress metrics per agent. A background thread detects stalls (no progress within a configurable threshold). When an agent stalls, its resources are automatically released.
guard.report_progress(agent_id, "steps_completed", 5)
# If no progress for 120 seconds → resources auto-released
Problem 2: Authority Deadlocks Are Invisible
Agent A says "B should handle this." B says "ask C." C says "check with A." Nobody holds a resource. No tool is blocked. But the system is completely stuck. No existing tool detects this.
AgentGuard's Delegation Tracker maintains a directed graph of active delegations and runs cycle detection on every new delegation.
result = guard.delegate(agent_a, agent_b, task="summarize document")
# result.cycle_detected == True if this would create a loop
Problem 3: AI Agents Don't Know Their Max Resource Needs
Banker's Algorithm requires every process to declare its maximum resource needs upfront. An OS process can do this. An LLM agent cannot -it has no idea how many API calls a complex research task will require.
AgentGuard's Demand Estimator learns resource patterns at runtime using statistical estimation (mean + k*stddev at configurable confidence levels) and runs a probabilistic Banker's Algorithm.
# No declare_max_need() needed -the system learns automatically
guard.register_agent("researcher", demand_mode=ag.DemandMode.Adaptive)
Three Ways to Use AgentGuard
1. Decorator (simplest)
from agentguard.langgraph import AgentGuard, guarded_tool
guard = AgentGuard()
guard.add_resource("api", 60)
agent = guard.register_agent("worker", max_needs={"api": 10})
@guarded_tool(guard, agent, "api")
def call_api(prompt):
return openai.chat(prompt)
2. Context Manager (explicit control)
with guard.acquire(agent, "api", 3, timeout=5.0) as status:
# 3 API slots acquired, auto-released on exit
result = openai.chat(prompt)
3. LangGraph ToolNode (drop-in)
from agentguard.langgraph import GuardedToolNode
node = GuardedToolNode(
tools=[search_tool, calc_tool],
guard=guard,
agent_id=agent,
tool_resources={"search_tool": {"api": 2}},
)
# graph.add_node("tools", node)
Getting Started
pip install agentguard-ai # core library
pip install "agentguard-ai[langgraph]" # + LangGraph integration
- GitHub: github.com/100rabhkr/AgentGuard
- 285 tests (189 C++ + 96 Python), MIT licensed
- C++ core for microsecond safety checks, Python bindings via pybind11
- Works with LangGraph, LangChain, or any Python multi-agent framework
Frequently Asked Questions
How do I prevent deadlocks in LangGraph?
Use AgentGuard's @guarded_tool decorator or GuardedToolNode to wrap your tool calls with automatic resource acquisition and release. AgentGuard uses the Banker's Algorithm to mathematically guarantee that granting a resource request won't lead to deadlock. Install with pip install "agentguard-ai[langgraph]".
Why do my LangChain agents get stuck in infinite loops?
There are two common causes: (1) resource deadlocks where agents hold resources and wait for each other, and (2) stuck agents in infinite reasoning loops. AgentGuard solves both -the Banker's Algorithm prevents resource deadlocks, and the Progress Monitor detects stuck agents and auto-releases their resources.
How do I share API rate limits across multiple AI agents?
Register the rate limit as a resource with AgentGuard: guard.add_resource("openai_api", capacity=60, category="api_rate_limit"). Each agent declares its maximum need, and AgentGuard ensures that resource allocation never leads to deadlock while maximizing throughput.
What is the Banker's Algorithm and how does it apply to AI agents?
The Banker's Algorithm (Dijkstra, 1965) is a deadlock prevention algorithm from operating systems. Before granting any resource request, it checks whether the system would remain in a "safe state" -meaning all agents can still complete. AgentGuard extends this with progress monitoring (stuck agent detection), delegation tracking (authority deadlock detection), and adaptive demand estimation (no upfront resource declarations needed).
Does AgentGuard work with CrewAI or AutoGen?
AgentGuard works with any Python multi-agent framework. The @guarded_tool decorator wraps any function, and the low-level agentguard module provides full control over resource management. LangGraph and LangChain have dedicated integrations (GuardedToolNode, AgentGuardCallbackHandler).
How much overhead does AgentGuard add?
The safety check runs in microseconds (C++ core, O(n^2 * m) complexity). For typical systems with <100 agents and <50 resource types, it's invisible. The C++ core is compiled to native code via pybind11 -no interpreter overhead for the critical path.
Do I need to declare maximum resource needs for every agent?
No. AgentGuard supports three modes: Static (classical, declare upfront), Adaptive (learns from usage, no declaration needed), and Hybrid (uses minimum of declared and estimated). Adaptive mode is recommended for LLM agents whose resource usage is unpredictable.
Is AgentGuard thread-safe?
Yes. The C++ core uses std::shared_mutex for read-heavy workloads (safety checks take shared locks, allocations take exclusive locks). Python's GIL is properly released during blocking calls and reacquired for callbacks. Multiple Python threads can safely use AgentGuard concurrently.